
چالش های پیاده سازی ratelimiter برای یک CDN - قسمت ۱
اگر جایی توی اینترنت با پیام
TOO_MANY_REQUESTS
روبرو شدید، احتمال خیلی زیاد اون وبسایت
rate limit
داشته و تعداد درخواست های شما از حد مجاز تعریف شده برای اون وبسایت بیشتر شده و
rate limit
شدید. به طور کلی
rate limit
روشی برای کنترل جریان هست. توی یک سد اگر میخوایم میزان عبور آب رو کنترل کنیم، میایم جریان آب رو محدود میکنیم به طوری که فقط
x
مقدار آب در بازه زمانی
t
بتونه عبور کنه. توی یک وب سرور این موضوع این طور تعمیم داده میشه که تعداد درخواست های یک کاربر (معمولا کاربران با
IP Address
شون متمایز میشن) در یک بازه زمانی
t
(مثلا ۱۰ ثانیهای) از x تا بیشتر نشه.نکته: منظور از بازه زمانی توی هر الگوریتم ممکنه متفاوت باشه که جلوتر در موردش صحبت میکنیم.
معمولا مسیر های حساس یا مسیر هایی که پردازش سنگینی نیاز دارند رو
rate limit
میکنن. مثلا اگر مسیری مثل
/auth/sendOTP
که کارش ارسال رمز یکبار مصرف به یک شماره هست،
rate limit
نداشته باشه، یک نفر میتونه به تعداد دفعات زیادی این
endpoint
رو صدا بزنه و اعتبار پنل
SMS
تون رو خالی کنه. حالا این
rate limit
کردن چطوری انجام میشه؟موضوع یک: الگوریتم ها 1
الگوریتم های مختلفی برای
rate limit
کردن وجود داره که هر کدومشون خوبی ها و بدی های خودشون رو دارن، اول همشون رو معرفی میکنیم
و میگیم چطوری کار میکنن و از آخر مقایسشون میکنیم، یکی رو انتخاب و ازش در ادامه مطلب استفاده میکنیم.
نمونه زیر رو در نظر میگیریم تا باهاش بتونیم الگوریتم هارو بفهمیم:
قانون rate limit ای که در بازه زمانی 10 ثانیه هر نفر که با IP Address اش متمایز میشه، اجازه داشته باشه ۵ درخواست HTTP ارسال کنه.
الگوریتم Fixed Window
توی الگوریتم
fixed window
اول یک مبدا شروع زمان در نظر میگیریم که معمولا توی پیاده سازی ها، از
Unix Time
استفاده میشه. بعد از مشخص کردن مبدا، از مبدا شروع میکنیم و هر
t ثانیه
یک علامت میزاریم
(که اینجا t همون ۱۰ ثانیه قانونمون هست).
در آخر بازه های بین هر علامت رو بازه زمانی قانونمون در نظر میگیریم و هر نفر اجازه داره فقط
x
(که توی مثال برابر با ۵ است) درخواست در این بازه ها ارسال کنه.

همینطور که توی تصویر ۲ میبینید، توی بازه زمانی اول ۵ درخواست اول قبول شدن (فلش های سبز) و ۲ درخواست بعدی بلاک شدن و در بازه زمانی دوم مجدد فقط ۵ درخواست اول بازه قابل قبول است.
یک نمونه پیاده سازی این الگوریتم به زبان Rust:
▼ میتونید با زدن روی دکمهRust Playgroundنسخه کامل و قابل اجراش رو ببینید.
struct Rule {time_duration: Duration,rate: usize,}/// State[int(now / time_duration)] -> counted requeststype State = HashMap<u128, usize>;fn is_rate_limited(origin: SystemTime,current_time: SystemTime,rule: &Rule,state: &mut State,) -> bool {let current_time_ms = current_time.duration_since(origin).unwrap().as_millis();let time_duration_ms = rule.time_duration.as_millis();let state_idx = current_time_ms / time_duration_ms;let t_state = state.entry(state_idx).or_insert(0);*t_state += 1;*t_state > rule.rate}
الگوریتم Leaky Bucket
در این الگوریتم درخواست ها قبل از پردازش شدن وارد یک صف میشن و منتظر میمونن.
این صف یک ظرفیت داره
(rate)
که اگر درخواست جدید اومد و صف پر بود،
درخواست بلاک میشه.
از این صف هر
t / rate ثانیه 2
یک المان کم میشه تا وقتی که صف خالی بشه.
این الگوریتم جدا از اینکه میتونه برای
rate limit
کردن استفاده بشه، میتونه به عنوان یک کنترل کننده جریان هم استفاده بشه
که درخواست ها با یک نرخ ثابت و کنترل شده انجام بشن.
نمونه پیاده سازی این الگوریتم به صورت async در زبان Rust:
struct Rule {time_duration: Duration,rate: u32,}type Request = (RequestResumer, Waiter);type Bucket = mpsc::Sender<RequestResumer>;async fn is_rate_limited(req: Request, bucket_tx: Bucket) -> bool {let (req, waiter) = req;match bucket_tx.try_send(req) {Ok(_) => {waiter.wait_in_queue().await;false}// queue is fullErr(_) => true,}}async fn leak(rule: Rule, mut bucket_rx: mpsc::Receiver<RequestResumer>) {loop {if let Some(resumer) = bucket_rx.try_recv().ok() {resumer.send(()).unwrap();}sleep(rule.time_duration / rule.rate).await;}}
الگوریتم Sliding Window Log ـ 3
این الگوریتم با ذخیره کردن timestamp هر درخواست کار میکنه.
وقتی یک درخواست جدید دریافت میکنیم:
- ابتدا تمام timestamp های قدیمی شده رو پاک میکنیم.
- درخواست جدید رو رکورد میکنیم
- در نهایت با چک کردن اندازه رکورد هامون، تصمیم میگیریم که request رو بلاک کنیم یا نه.
بیایم اینو با مثالی که
بالا
زدیم، باز کنیم:

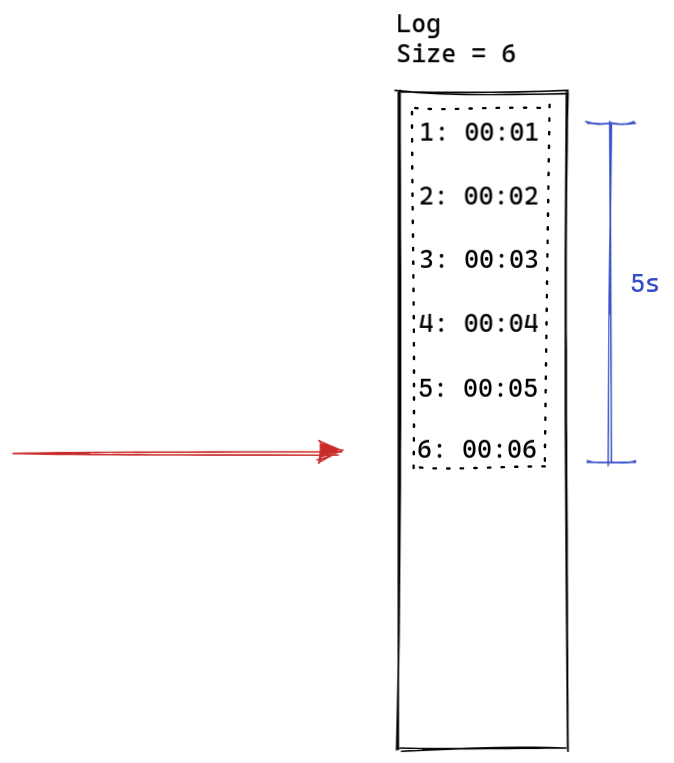
در ابتدا ۵ درخواست داریم که هر کدوم با فاصله های زمانی یک ثانیهای به سمت ما ارسال میشن.
چون از قبل رکوردی نداریم و زمان ها در بازه
threshold
هستند(جلوتر میفهمیم این چیه)
هیچکدوم پاک نمیشن و همشون ثبت میشن. لاگمون الان اندازش ۵ هست و
چون بزرگتر از rate امون نیست،
لازم نیست آخرین درخواست رو بلاک کنیم. میریم جلوتر:
یک ثانیه بعد یک درخواست جدید میاد، همه رکورد های قبلی توی بازه زمانیمون قرار دارن
(نقطه چین)
در نتیجه هیچ رکوردی حذف نمیشه. درخواست فعلی رو رکورد میکنیم. چون اندازه
لاگمون بیشتر از ۵ شد، باید درخواست رو بلاک کنیم.
بازه زمانی توی sliding window log میشه بازه درخواست فعلی تا t ثانیه4 قبل.
بریم جلوتر:
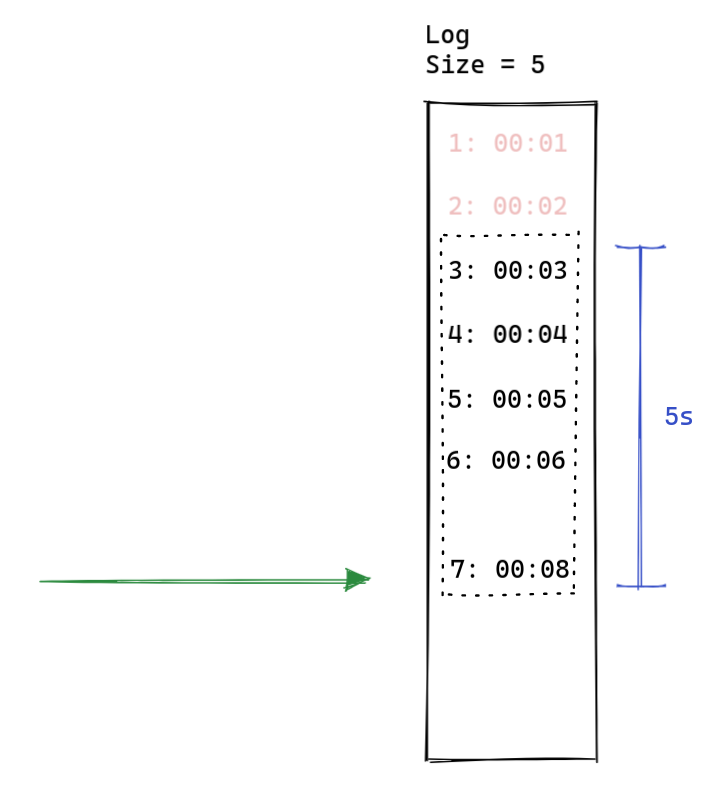
۲ ثانیه بعد، یک درخواست جدید میاد.
چون رکورد های ۱ و ۲ خارج از بازه زمان هستن، اونارو از لاگمون پاک میکنیم،
بعد درخواست فعلی رو رکورد میکنیم. چون اندازه لاگمون بیشتر از ۵ نیست،
لازم نیست درخواست رو بلاک کنیم. این الگوریتم به همین ترتیب برای درخواست بعدی
عمل میکنه.
یکی از خوبی های این الگوریتم، تعریف متفاوت اون از بازه نسبت به
الگوریتم fixed window هست.
بازه ها توی
fixed window
ثابت اما اینجا پویاست. در نتیجه این الگوریتم گارانتی میکنه که درخواست هایی فقط
قبول میشن که تعداد درخواست ها
از t ثانیه قبلشون تا به الان
از حد قانون یا rate
بیشتر نباشه.
اما در fixed window این گارانتی وجود نداره در نتیجه اگه قانونی مثل
rate=1000, t=24hr داشته باشیم و فرض کنیم
origin همان ابتدای روز است،
اگه کاربر از ۹ تا ۱۰ صبح 1000 درخواست خودش رو مصرف کنه، دیگه اجازه نداره تا روز بعدی درخواست جدیدی بفرسته.
اما توی sliding window اینطور نیست و بعد از ظهر میتونه
مجدد درخواست ارسال کنه. نه
1000 تا
، کمتر ولی دسترسیش کامل از سایت قطع نمیشه.5
بجاش صبح روز بعد کمتر از 1000 تا درخواست میتونه ارسال کنه.این الگوریتم بدی هم داره، مموری زیادی نسبت به الگوریتم های دیگه مصرف میکنه و تحت کنترلمون نیست.
توی fixed window
ما میدونیم که هر کاربر یک اندازه ثابت مموری نیاز داره و بیشتر نمیشه
(مثلا ۱۲۸ بایت ثابت)
اما توی sliding window log
چون ما باید لیستی از لاگ ها رو برای هر کاربر ذخیره کنیم، دقیقا نمیدونیم که هر کاربر چقدر مموری نیاز داره.
مثلا یک کاربر میتونه نسبت به درخواست هایی که میده ۱۰ مگابایت مموری مصرف کنه و
یک کاربر دیگه ۱۰۰ کیلوبایت.
مشکل دیگهای هم که داره اگه از یک کاربر ۵ مگابایت رکورد داشته باشیم و این کاربر هیچوقت دیگه
به سایتمون سر نزنه، هیچ وقت رکورد های قدیمی رو پاک نمیکنیم و این ۵ مگ رو الکی نگه داشتیم و از منابع به خوبی استفاده نکردیم.
در نتیجه باید یک فرایند پسزمینهای داشته باشیم که هرچند وقت یکبار همه رکورد ها برای همه کاربر هارو
بررسی کنه و رکورد های قدیمی رو پاک کنه. اگه این کار رو هم انجام بدیم مشکلات همزمانی
خودشون رو نشون میدن که اگه اونارو هم با لاک کردن حل کنیم، روی پرفرمنس تاثیر زیادی میزارن
که برای سیستمی که بار سنگینی رو پردازش میکنه
(مثل CDN)
اصلا ایدهآل نیست. جلوتر توی این نوشته بیشتر در این مورد صحبت میشه.
نمونه پیاده سازی این الگوریتم در زبان Rust:
struct Rule {time_duration: Duration,rate: usize,}type Log = Vec<u128>;fn is_rate_limited(current_time: SystemTime, rule: &Rule, log: &mut Log) -> bool {let current_timestamp = current_time.duration_since(UNIX_EPOCH).unwrap().as_millis();let time_duration_ms = rule.time_duration.as_millis();// cleanuplet mut logs_to_pop = 0;for timestamp in log.iter() {if *timestamp < current_timestamp - time_duration_ms {logs_to_pop += 1;}}log.drain(0..logs_to_pop);if log.len() >= rule.rate {true} else {// appendlog.push(current_timestamp);false}}
الگوریتم Sliding Window ـ 6
این الگوریتم میاد مشکل الگوریتم
fixed window
که توی بازه های زمانی ثابت، شمارنده رو صفر میکنه رو حل میکنه،
به این صورت که دو شمارنده داره، یکی برای
پنجره ثابت فعلی
و یکی برای قبلی. به شمارنده قبلی یک وزن میده و با شمارنده فعلی جمعش میکنه
تا یک تقریب نسبتا خوبی برای rate بدست بیاره
و در نهایت اونو با
rate
قانونمون چک میکنه. بیایم برای اینکه بهتر بفهمیم، مثل الگوریتم قبل اینم
با مثال
بالا
بازش کنیم:
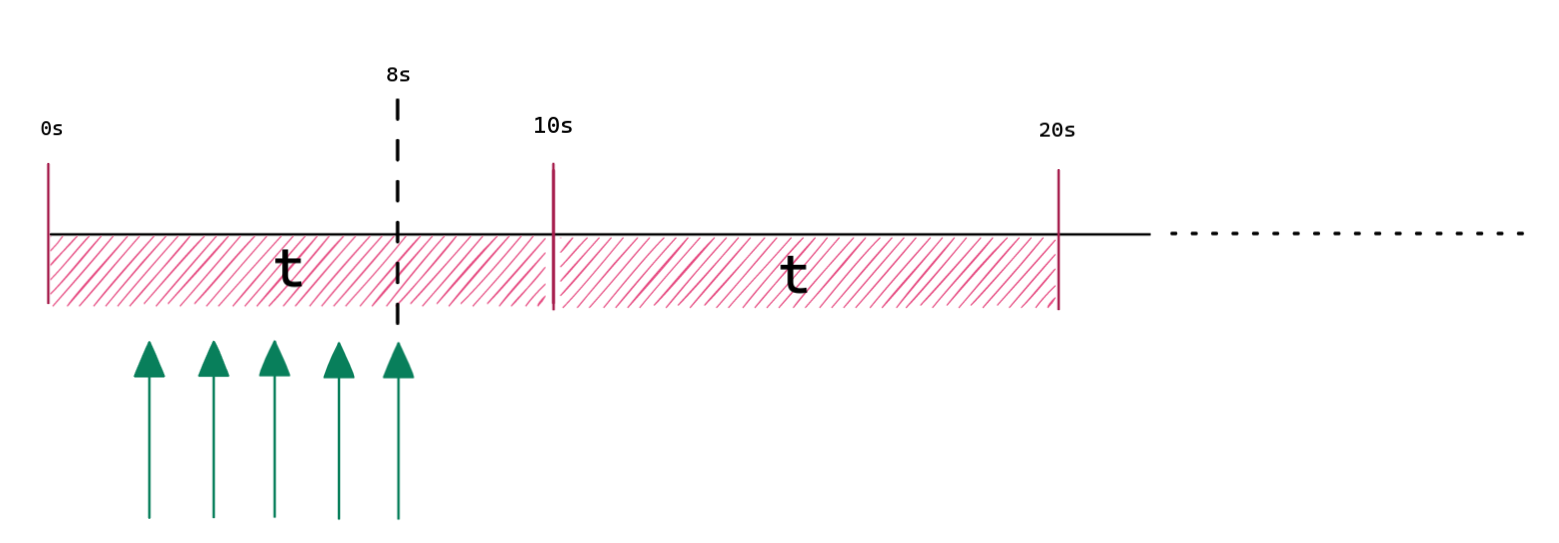
فرض میکنیم اول ۵ تا درخواست اومدن و مثل تصویر بالا توی ثانیه 8ام، آخرینشون رو شمردیم.
توی ثانیه 12ام یک درخواست جدید میاد:

یک بازه به اندازه t که اینجا
10 ثانیه هست در نظر میگیریم و آخرش رو زمان فعلی درخواستمون میزاریم.
اول این بازه میوفته توی
current_time - t که توی این مثال میشه
ثانیه 2م.
حالا باید ببینیم که چند درصد این بازه توی
پنجره ثابت
قبلی افتاده که اینجا میشه
80 درصد در نتیجه وزنمون میشه 0.8. شرط چک کردنمون میشه:rate = last_rate * weight + current_raterate = 5 * 0.8 + 0 = 4
چون عددی که بدست اوردیم کمتر از
rate
قانونمونه، درخواست بلاک نمیشه و به شمارنده پنجره ثابت فعلی یکی اضافه میکنیم.
وقتی هم میریم به پنجره بعدی (مثلا بریم بعد از ثانیه 20ام)
میایم مقدار
current_rate رو میریزیم توی last_rate و
current_rate رو صفر میکنیم.یک نمونه پیاده سازی کامل این الگوریتم:
struct Rule {time_duration: Duration,rate: usize,}struct State {/// last time we counted a requestpub last_count_time: Instant,/// last block request countpub last_window_count: usize,/// current window request countpub current_window_count: usize,}fn is_rate_limited(origin: Instant, current_time: Instant, rule: &Rule, state: &mut State) -> bool {let duration_since_last_req = current_time.duration_since(state.last_count_time);if duration_since_last_req >= rule.time_duration * 2 {state.last_window_count = 0;state.current_window_count = 0;} else if duration_since_last_req > rule.time_duration {state.last_window_count = state.current_window_count;state.current_window_count = 0;}let t_ms = rule.time_duration.as_millis();let current_window_start = {let normal = current_time.duration_since(origin).as_millis() / t_ms;origin + Duration::from_millis((normal * t_ms) as _)};let w = {let d = current_time - current_window_start;let dp = if d > rule.time_duration {Duration::ZERO} else {rule.time_duration - d};(dp.as_millis() as f64) / t_ms as f64};let count = ((w * state.last_window_count as f64) as usize) + state.current_window_count;if count >= rule.rate {return true;}state.last_count_time = current_time;state.current_window_count += 1;false}
توی پیاده سازی بالا ما زمان آخرین درخواست هم ذخیره میکنیم این به این دلیل هست که چک کنیم که اگه درخواست جدید با آخرین درخواست ۲ تا بازه زمانی فاصله داشته باشن، بیایم وcurrent_rateوlast_rateرو صفر کنیم.
مقایسه و انتخاب یک الگوریتم
حالا که با 4 تا از الگوریتم های
rate limit
آشنا شدیم، بیایم اینارو با هم مقایسه کنیم و در نهایت یکی از اونهارو
برای استفاده توی
CDN
مون انتخاب کنیم.
مموری
fixed windowبرای هر کاربر مموری ثابتی نیاز داره و رشد نمیکنه.leaky bucketمموری ثابتی نداره اما حداکثر مورد نیاز نسبت به قانون مشخص میشه.sliding window logبرای هر کاربر مموری رشد میکنه و حداکثری وجود نداره.sliding windowبرای هر کاربر مموری ثابتی نیاز داره و رشد نمیکنه.
درستی
fixed windowاین مشکل رو داره که شمارنده ها یکدفعه در تایم های مشخص ریست میشن.leaky bucketرفتاری داره که کاربران معمولا انتظار اون رو ندارن. معمولا وبسایت ها میخوان که توی یک بازه زمانی یک تعداد فقط درخواست رد بشه نه اینکه در یک بازه زمانی با یک نرخ ثابت درخواست داشته باشیم. این باعث میشه استفاده کننده به اشتباه بیوفته.sliding window logدرستترین خروجی رو داره.sliding windowخروجی تقریبی اما خیلی خوبی داره.
از لحاظ مموری
fixed window و sliding window
بهترین هستند و درستترین بین این دوتا،
sliding window هست.
پس بهتره در ادامه کار، با این الگوریتم جلو بریم.در
قسمت بعد
، به این میپردازیم که این الگوریتم در محیط همزمان توی یک سرور چطور عمل میکنه.
پانویس
- در عمل ممکنه بعضی از الگوریتم ها با یکم تغییر پیاده سازی شده باشن.↩
- یا هر واحد زمانی دیگر↩
- با نام Sliding Log هم شناخته میشود↩
- یا هر واحد زمان دیگه↩
- این میتونه هم خوب باشه هم بد ولی اکثر استفاده کنندگان ratelimit، این مدل رو بیشتر ترجیح میدن.↩
- پیاده سازی های مختلفی از این الگوریتم برای RateLimit وجود داره ولی ما تارگتمون پیاده سازی کلادفلیر هست↩