
V8 چیه و چطور کار میکنه؟ - قسمت ۱
این قسمت از سری و احتمالا چند قسمت بعدی اون، خلاصه و ساده شده منابع آخر مطلبه که من اومدم بینش یکسری مطالب دیگهرو هم بهش اضافه کردم یا برای یک مطلبی توضیح بیشتر دادم.
V8 یک موتور برای اجرای جاوااسکریپت و وباسمبلی هست که
در نرمافزار های مختلفی مثل
Google chrome
و
nodejs
استفاده میشه. این موتور پرفرمنس خیلی بالایی داره و دلیلش خلاقیت و تکنولوژی های جالبی هست که توش استفاده کردن.
هدف این پست اینه که بیاد این پروژه رو معرفی کنه و تا حد خوبی به جزئیات اینکه چطور کار میکنه بپردازه.
مرحله اول - تولید Abstract Syntax Tree
برای اینکه بشه یک کد جاوااسکریپت رو اجرا کرد٬ باید اول کد اونو به یک فرمت مخصوصی تبدیل کنیم که موتور
v8 راحتتر بتونه باهاش کار کنه.
این فرمت Abstract Syntax Tree یا AST هست که نشون دهنده ساختار اصلی کده و همه داده های اضافه مثل کامنت
و اسپیس از اون حذف شده.
مثلا اگر همچین کدی داشته باشیم:
function salam() {const b = "hello";console.log(b);return 1;}var result = salam();
AST اون میشه همچین چیزی:
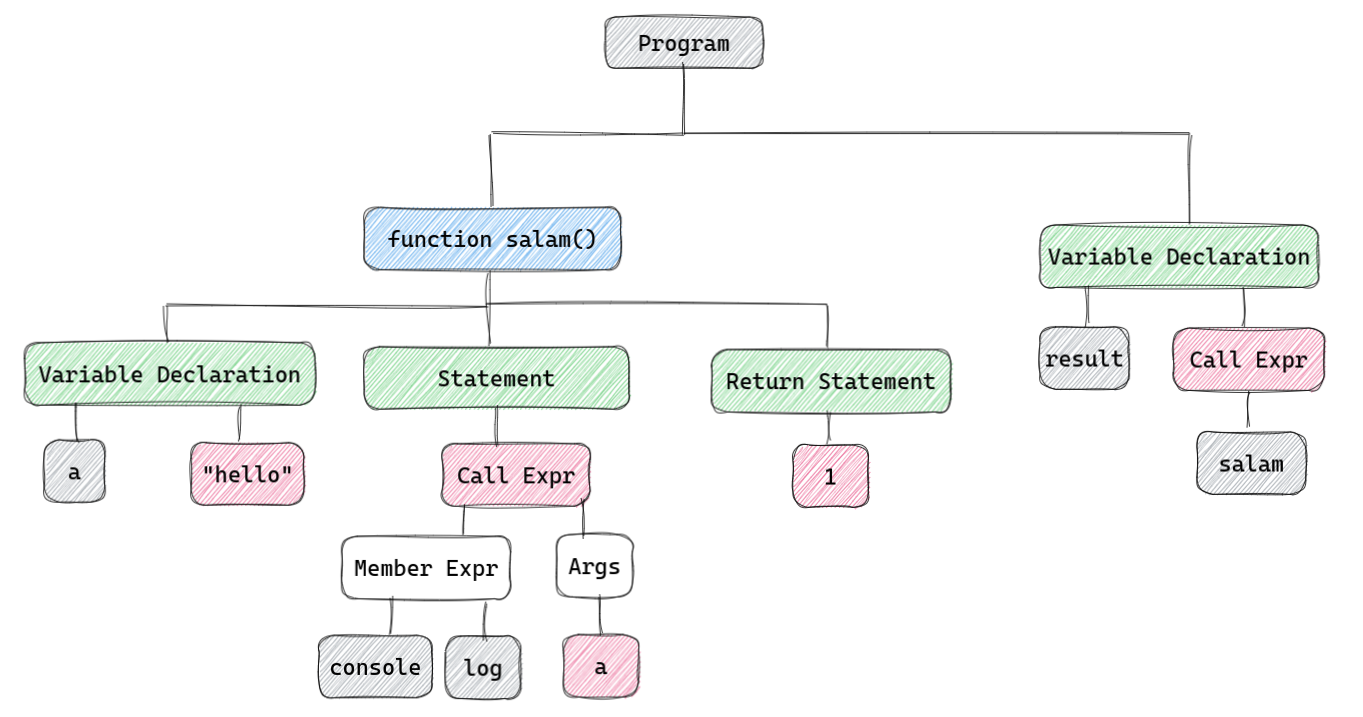
برای اینکه V8 این AST رو تولید کنه٬
، باید این مراحل رو طی کنه:

بریم ببینیم هر مرحلهاش داره چیکار میکنه.
توی V8 چون تا وقتی AST نداشته باشیم نمیتونیم هیچکاری انجام بدیم٬ V8 میاد AST رو به صورت streaming تولید میکنه. خیلی ساده یعنی مثلا توی کد بالا٬ وقتی تمام کاراکتر های مورد نیازش برای تابع اول رو دریافت کرد یک Node توی AST ایجاد میکنه و اونو بر میگردونه ولی میگه هنوز کارش تموم نشده. اینطوری V8 میتونه مثلا تابع اول رو اجرا کنه با اینکه هنوز بقیه کد رو parse نکرده.
Scanner ـ 1
کامپایلر هر زبان برنامهنویسی برای اینکه بتونه خروجی تولید کنه٬ باید اول بتونه کدهای شمارو بفهمه. اولین قدم فهمیدن٬
بررسی رشته ورودیای هست که بهش دادین. اگه کد زیر رو داشته باشیم:
if (allow == true) {console.log("welcome");}
کامپایلر باید توالی کاراکتر های ورودی رو بخونه و اونو تبدیل به توکن کنه که کار فهمیدن راحتتر بشه:
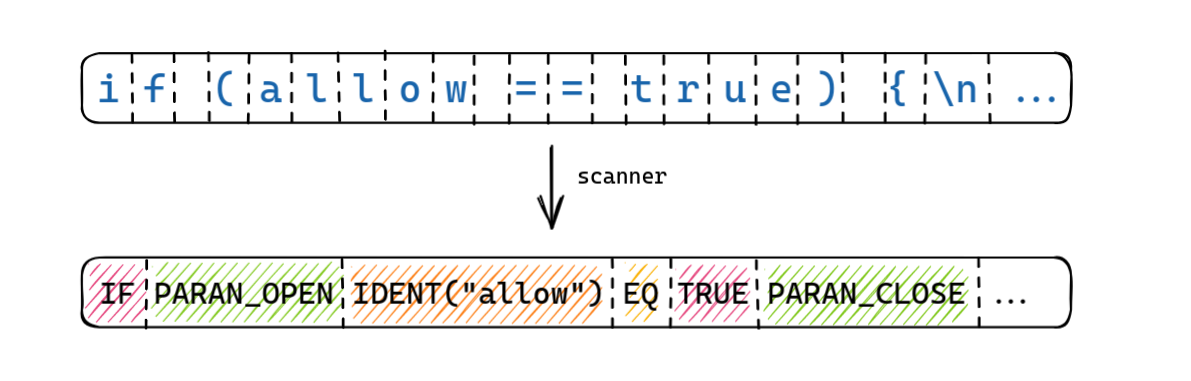
فرض کنیم تصویر بالا٬ ساده شده یک scanner برای جاوااسکریپت هست.
کدی رو دادیم بهش و اون توی خروجی بهمون یک توالی از token ها داده.
کار کردن با این توکن ها برای فهم کد به مراتب راحتتر از مستقیم کار کردن روی کاراکتر هاست.
مثلا بعدا اگر بخوایم بفهمیم که آیا کاربر اینجا یک شرط نوشته باید دنبال یک الگو از توکن های پشت سر هم باشیم مثلا:
[..., IF, PARAN_OPEN, IDENT, PARAN_CLOSE, ...]
یا
[..., IF, PARAN_OPEN, KEYWORD, PARAN_CLOSE, ...]که پیدا کردن این الگو به کمک لیست توکن ها خیلی سادهتر هست. این قسمت یک نکته مهمی که داره اینه که ممکنه همچین ورودی داشته باشیم:
if if if true
که توی جاوااسکریپت معنی نمیده ولی
scanner
باز هم توالی توکن
[IF, IF, IF, TRUE]
رو تولید میکنه و تایید اعتبار ترکیب درست توکن ها کنار هم توی مرحله بعد یعنی پارسر انجام میشه.نکته: داخل scanner بالا کاراکتر های اضافه مثل فاصله و خط جدید هم حذف شدن ولی لزوما هر کامپایلری این کار رو توی این مرحله انجام نمیده.
به این تیکه از کامپایلر٬ scanner میگن.
اسم های دیگهای هم داره مثل lexer و tokenizer
ولی چون توی v8 از scanner استفاده شده٬ توی این مقاله هم با این اسم میریم جلو.
وقتی یک اپلیکیشن دسکتاپ درست میکنیم معمولا اونو کامپایل میکنیم و خروجی باینری اونو به کاربر میدیم. پس اونقدر
سرعت کامپایلر نباید اهمیت داشته باشه. اما توی جاوااسکریپت سیستم کاربر کد رو از ما میگیره و خودش کارهای
interpreting و compile
رو انجام میده.
اینجاست که نوشتن یک کامپایلر سریع خیلی مهم میشه چون هرچی این کامپایلر سریعتر باشه٬ سایت کاربر سریعتر بالا میاد.
به همین علت موتور
v8
نیاز داشته که یکسری کارهای خاص انجام بده که سرعت مراحل مختلف کامپایل بالاتر بره.
مثلا:
Comment
توی پایتون توی رانتایم میتونیم کامنت های یک تابع رو بخونیم. در واقع کامنت ها یک رشته هستن:
def foo():"""comment"""returnprint(foo.__doc__) # comment
توی زبان
C# میتونیم با انتخاب خودمون از طریق
Reflection
کامنت های از نوع Docstring رو بخونیم.همینطور توی زبان rust کامنت های
// ایگنور میشن ولی برای کامنت های نوع
Docstring یا //!
توکن درست میشه چون توی سیستم ماکرو اش میتونیم داکیومنت جنریت کنیم.اما توی جاوااسکریپت موتور v8 برای اجرا هیچ نیازی به کامنت ها نداره برای همین بهتره که خیلی سریع از روشون بگذره.
لازم نیست که برای سریعتر اجرا شدن سایتتون از این به بعد کامنت نزارید. ابزارهایی که دارید همینکار رو موقع build گرفتن براتون میکنن. مثلا ابزار UglifyJs که اگر به پروژه هاتون نگاه کنید٬ پیداش میکنید.
identifier scanning
توی v8 پیچیدهترین اما پراستفاده ترین توکن٬
توکن
IDENTIFIER هست
که برای
Identifier
تعریف شده داخل داکیومنت فنی
ECMAScript
تولید میشه. اسم توابع و متغییر ها٬ Identifier هستن که احتمالا به این موضوع برخوردید که یکسری محدودیت توی انتخاب کاراکتر ها داره:- ID_START: اولین کاراکتر باید
[a-z]٬[A-Z]٬$یا_باشه. - ID_CONTINUE: در صورت بیشتر از یک حرفی بودن٬ بقیه کاراکتر ها یا باید ID_START باشن٬ یا عدد.
یکی از مهمترین دلایل این محدودیت٬ کاهش ابهام یا ambiguity توی زبان هست.
فرض کنیم کاراکتر
- یک کاراکتر مجاز توی identifier باشه. اگه کد زیر رو داشته باشیم:var a = 2;var b = 1;var a-b = 0;if (a-b == 0) {console.log("A");} else {console.log("B");}
چنتا برداشت میتونیم داشته باشیم:
- برداشت ۱:
a-bاشاره میکنه به مقدار داخل متغییر تعریف شده با همین نام. - برداشت ۲: مقدار متغییر با نام
bاز مقدار متغییر با نامaکم میشه و حاصلشون با صفر مقایسه میشه.
اگر بخوایم هرکدوم از اینارو پیاده سازی کنیم
باید برای تولید هر توکن بیایم همه توکن های قبلی رو چک کنیم
و مطمینم بشیم که همچین Identifier ای رو کاربر قبلا تعریف کرده یا نه و نسبت به اون ۱ توکن درست کنیم یا ۳ تا توکن.
توی زبان جاوااسکریپت یک تابع بنام
eval داریم که اجازه بهمون میده کد های داینامیک اجرا کنیم که باز کارو پیچیدهتر هم میکنه.برای اینکه بتونیم یک scanner سریع بنویسیم
هرچی کار کمتری داشته باشیم٬ کارمون هم سریعتر تموم میشه. این ابهامات پیچیدگی و درنتیجه حجم کارمون رو بیشتر میکنن و درنهایت
یک scanner کند خواهیم داشت.
حالا چون این توکن پراستفادهترین توکن هست٬ اضافه کردن کوچیکترین پیچیدگی هم باعث کاهش پرفرمنس میشه.
توی جاوااسکریپت چون identifier خیلی محدود هست کار اسکنر هم خیلی ساده میشه
کافیه وقتی به یک ID_START رسید٬ تا وقتی که کاراکتر های بعدی ID_CONTINUE هستن اونارو بعنوان
identifier درنظر بگیره و نیاز نیست تحلیل خاصی هم روی تک تک کاراکتر ها انجام بده.
Keywords
keyword ها زیرمجوعه identifier هستن.
برای مثال وقتی scanner به عبارت
if میرسه٬ این عبارت رو مثل یک
identifier اسکن میکنه ولی وقتی میخواد توکن برگردونه٬
باید چک کنه که اگر عبارت یکی از keyword ها بود٬ بجای توکن
IDENT٬ توکن مربوط به keyword رو برگردونه که توی مثال ما میشه
توکن IF.
چون این چک کردن باید برای هر identifier انجام بشه و قبلتر گفتیم که معمولترین توکن٬ IDENT هست٬
این چک کردن رو هرچی بهینهتر پیاده سازی کنیم٬ میتونه تاثیر قابل توجهی روی پرفرمنس بزاره.یک پیاده سازی ساده اون٬ میتونه استفاده از
HashMap باشه:const keywords = {'if': Token.IF,'function': Token.FUNCTION,// ...};function getKeyword(ident) {return keywords[ident];}
پیچیدگی زمانی
HashMap یا HashTable٬ O(1) در حالت میانگین هست.
در بدترین حالت اما این پیچیدگی زمانی O(n) هست.
بدترین حالت وقتی پیش میاد که ما collision داشته باشیم.
برای فهمیدن این مشکل باید بدونیم یک HashMap چطور کار میکنه.فرض کنیم ما توی زبانی که داریم استفاده میکنیم فقط
List داریم و نیاز داریم یک
HashMap پیاده سازی کنیم.
اولین چیزی که نیاز داریم٬ یک hash function هست.
کار این تابع اینه که از ورودی یک مقداری با هر اندازه ای رو بگیره و یک مقدار با اندازه ثابت بهمون بده.
مثلا یک string بگیره و یک u32 بهمون بده. md5, sha256 دوتا hash function معروف هستن که
احتمالا باهاشون قبلا کار کردید. اینجا اما تابعی مثل
crc32
بیشتر بدرد میخوره.اگه بیایم مقادیر زیر رو به این تابع بدیم٬ خروجی های زیر تولید میشه:
console.log(crc32('if')); // 1362560636console.log(crc32('function')); // 3400406589console.log(crc32('while')); // 3235141117
اینجا میتونید آنلاین این تابع رو امتحان کنید.
حالا ما یک تابعی داریم که هر رشته ای رو تبدیل به یک عدد بین
0 تا 4294967295 میکنه.
میتونیم الآن یک آرایه داشته باشیم که اندازش 4294967296 باشه و برای پیاده کردن یک المان کافیه هش کلید اون رو بدست بیاریم
و نتیجش میشه index ای که مقدار کلیدمون توش قرار داره:class HashTable {elements: [];function insert(key, value) {const idx = crc32(key);this.elements[idx] = value;}function get(key) {const idx = crc32(key);return this.elements[idx];}}const table = new HashTable();table.insert("a", 1);table.insert("b", 2);console.log(table.get("a")); // 1console.log(table.get("b")); // 2console.log(table.get("c")); // undefined
این پیاده سازی ۲ تا مشکل داره:
- اگه دوتا مقدار مختلف یک هش یکسان داشته باشن٬ توی یک خونه قرار میگیرن و collision داریم.
- حافظه زیادی میگیره چون نیاز داریم برای هر
HashMapیک لیست به اندازه4294967296المان داشته باشیم.
بیایم اول مشکل اولی رو حل کنیم. بیایم بجای اینکه داخل هر المان یک مقدار ذخیره کنیم٬ یک لیستی از مقادیر ذخیره کنیم و وقتی
به collision رسیدیم٬ مقدارمون رو به اون لیست اضافه کنیم.
وقتی هم میخوایم یک المان رو lookup کنیم اول با هش توی لیست اصلی مستقیم به خونه مورد نظرمون میرسیم٬
بعد میایم یک سرچ خطی توی آرایه داخلی میزنیم. دلیل اینکه بدترین حالت
O(n) هست هم همینجاست٬ چون مجبوریم اینجا سرچ خطی انجام بدیم.
class HashTable {elements: [];function insert(key, value) {const idx = crc32(key);let bucket = this.elements[idx];if (bucket == null) {bucket = [];this.elements[idx] = bucket;}const oldValueIdx = bucket.findIndex(x => x.key == key);if (oldValueIdx == -1) {bucket.push({ key, value });} else {bucket[oldValueIdx] = { key, value };}}function get(key) {let idx = crc32(key);let bucket = this.elements[idx];if (bucket == null)return null;return bucket.find(x => x.key == key);}}const table = new HashTable();table.insert("a", 1);table.insert("b", 2);console.log(table.get("a")); // 1console.log(table.get("b")); // 2console.log(table.get("c")); // null
مشکل دوم اینه که الآن پیاده سازیمون مموری زیادی میگیره. مثلا اگه هش
"a" رو حساب کنیم میشه 3904355907.
یعنی مقدارش باید توی خونه 3904355907 قرار بگیره و همه خونه قبلی لیستمون خالی و بدون استفاده هستن.
برای رفع این مشکل میتونیم یک محدوده حافظه مشخص کنیم. مثلا بگیم اندازه لیستمون فقط 100 المان باشه
و برای پیاده کردن index درست٬ کافیه مقدار هش رو بر اندازمون تقسیم کنیم و باقی موندش رو بعنوان index استفاده کنیم:یکی از پر استفاده کارای عمل باقی مونده، همین تبدیل یک رنج بزرگ به یک رنج کوچیکتر با اندازه مشخص هست.
const CAPACITY = 100;class HashTable {elements: [];function insert(key, value) {const idx = crc32(key) % CAPACITY;let bucket = this.elements[idx];if (bucket == null) {bucket = [];this.elements[idx] = bucket;}const oldValueIdx = bucket.findIndex(x => x.key == key);if (oldValueIdx == -1) {bucket.push({ key, value });} else {bucket[oldValueIdx] = { key, value };}}function get(key) {let idx = crc32(key) % CAPACITY;let bucket = this.elements[idx];if (bucket == null)return null;return bucket.find(x => x.key == key);}}const table = new HashTable();table.insert("a", 1);table.insert("b", 2);console.log(table.get("a")); // 1console.log(table.get("b")); // 2console.log(table.get("c")); // null
دقت کنید که یک پیاده سازی یک HashMap خیلی پیچیدهتر از چیزی هست که بالا نوشته شده و متن بالا فقط ایده اصلی Hash Table رو توضیح میده.
دیدیم که استفاده از
HashMap لزوما همیشه O(1) به ما نمیده و نسبت به شرایط ممکنه بیشتر طول بکشه.
بدلیل همیشه مشخص نبودن پرفرمنس HashMap٬ v8 از چیزی به نام Perfect Hash Function استفاده میکنه.
PHF ها دسته توابع هش ای هستند که اگر ما
n ورودی مختلف داشته باشیم٬
میتونه تابعی به ما بده که خروجیش یک عدد بین
۱ تا n هست.
شبهکد زیر رو نگاه کنید:let hasher = new PerfectHash(["a", "b", "c"]);console.log(hasher.hash("a")) // 0console.log(hasher.hash("b")) // 1console.log(hasher.hash("c")) // 2console.log(hasher.hash("e")) // error
حالا چون ما تمام keyword هامون رو میدونیم٬ میتونیم از
این روش استفاده کنیم و یک hash function مخصوص خودمون رو داشته باشیم.
حالا اگر این تابع هش رو توی پیاده سازی hash table مون دخیل کنیم٬
میتونیم یک lookup با هزینه زمانی بدترین حالت
O(1) داشته باشیم٬ چون
هیچوقت collision نخواهیم داشت.لیست همه keyword های جاوااسکریپت رو میتونید اینجا ببینید.
Whitespace
برای کاراکتر فاصله٬ خط جدید٬ تب و کامنتها٬
یک توکن
WHITESPACE توی v8 تولید میشه.
اکثر پارسر ها میان کلا این کاراکتر هارو درنظر نمیگیرن و هیچ توکنی هم براشون درست نمیکنن ولی
v8 نیاز داره براشون توکن تولید کنه.
یکی از اصلیترین دلایلش٬
Automatic Semicolon Insertion
هست که توی داکیومنت فنی
ECMAScript
اومده. توی جاوااسکریپت اجازه داریم که توی کدمون ; رو حذف کنیم که این قابلیت یکسری پیچیدگی ها برامون اضافه میکنه. مثال زیر رو نگاه کنید:returna + b
این کد به دو صورت میتونه تحلیل بشه:
حالت اول
return a + b;
حالت دوم
return;a + b;
که یکیشون مقدار برمیگردونه و اون یکی نمیکنه.
v8 حالت دوم رو در نظر میگیره حتی اگر ممکنه اشتباه باشه چون به کد اصلی که کاربر نوشته نزدیکتره و برای اینکه بتونه اینکارو بکنه
باید بدونه که بعد
return خط جدید درست شده و برای همین هم به توکن WHITESPACE نیاز داره.یک مثال دیگه:
a = b++c// after automatic semicolon insertion:a = b;++c;
:نکته مهم تو بعضی شرایط اینکارو رو انجام نمیده
(بخاطر backward compatibility):
a = b + c(d + e).print();// same asa = b + c(d + e).print();a = c[0].toString();// same asa = c[0].toString();
درست هندل کردن whitespace ها توی اسکنر/پارسر ای که مینویسی بطوری که کد رو اسپاگتی نکنه٬ یکی از چالش های پارسر نوشتن هست.
Parser ـ 2
پارس کردن مرحلهای است که سورس کد شما تبدیل به یک فرمت میانی قابل استفاده توسط کامپایلر میشه. چون پارس کردن در مسیر اصلی پردازش شدن یک وبسایت انجام میشه و روی لود شدن اولیه اون تاثیر مستقیم داره، خوبه که هیچ کار اضافهای انجام ندیم.
همه تابع های کد شما برای استارتاپ و اجرای اولیه سایت شما لازم نیستن. مثلا اگه از فریمورک react استفاده میکنید٬
کامپوننت های شما فانکشن اند و لزوما توی یک صفحه همه کامپوننت ها دیده نمیشن.
اگه بخوایم همه کد رو همون اول پارس و کامپایل کنیم (کامپایل اینجا یعنی تبدیل
ast به bytecode موتور ignition v8 هست)٬
منابع سیستم رو به خوبی استفاده نکردیم.
توی v8 یک چیزی هست به نام bytecode flushing که میاد تیکه کد هایی که خیلی وقته استفاده نشدن یا کلا دیگه امکان استفاده شدنشون وجود نداره رو از مموری خارج میکنه. میشه روی این فیچر حساب باز کرد که کدهای استفاده نشده مموری مصرف نکنن اما این نکته رو باید در نظر داشته باشیم که اگه ما همون اول بیایم همه کد رو ببریم توی رم ۱-لود اولیه سایت رو کند کردیم ۲-تا وقتی که سایکل bytecode flushing انجام نشه٬ مموری رو اشغال کردیم و اگه سیستم رمش توی این لحظه پر باشه٬ باز سایت خیلی کندتر و حس سنگینی زیادی باز میشه. در نهایت ۳- خود این فرایند نیاز به پردازش داره و ممکنه زمانبر باشه.
مرورگرها برای بهتر کردن این مسئله٬ کد هارو به صورت lazy پارس میکنن و ast ای تولید نمیکنن.
v8 علاوه بر این میاد میان کد رو pre-parse هم میکنه.
توی قسمت بعدی با جزئیات بیشتر به نحوه کار کردن parser و pre-parser میپردازیم.