🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧در دست نگارش🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧🚧
چالش های پیاده سازی ratelimiter برای یک CDN - قسمت ۲
این مطلب ادامه قسمت ۱ سری «چالش های پیاده سازی ratelimiter برای CDN» هست و فرض میکنه که شما قبلا اون رو مطالعه کردید.
همه وبسرور ها این قابلیت رو دارن که تعداد زیادی از درخواست هارو همزمان با هم قبول کنن. با
thread, async
یا حتی با استفاده از
sub-process. اگر یک نفر چند درخواست همزمان ارسال کنه، سرور چطوری
ratelimit
اونو حساب میکنه؟ توی این قسمت به این موضوع نگاه میکنیم.
اشتراک منابع
تقریبا هر موقع که
concurrency داریم
، باید به این فکر کنیم که
منابع همزمان چطور میتونن دست چند چیز (مثل thread)
باشن. توی مسئله ما، چونکه ممکنه وب سرورمون درخواست های مختلف یک نفر رو با ترد های مختلفی هندل کنه،
و ما باید شمارنده های الگوریتممون بین این ترد ها مشترک باشن، ما هم این مسئله رو داریم و باید یک راه حل براش
در نظر بگیریم.
Mutex
بیایم اول از
Mutex Lock
استفاده کنیم که راهحل سادهای رو به ما میده تا بتونیم اهمیت این موضوع رو درک کنیم.
برای سادگی موضوع، در نظر بگیریم یک وبسرور داریم که عدد ۱ تا ۱۰۰۰ رو باید با هم جمع کنه
و وقتی داره اینکارو میکنه، ترد های دیگه باید منتظر این کار باشن.
fn do_work(lock: &Arc<Mutex<()>>, no_lock: bool) -> usize {let _lock_guard;if !no_lock {_lock_guard = lock.lock();}let mut result = 0;for i in 1..=1000 {result += i;}result}pub struct WebServer {threads: Vec<(usize, Sender<()>, JoinHandle<usize>)>,}impl WebServer {pub fn new(num_threads: usize, no_lock: bool) -> Self {let lock = Arc::new(Mutex::new(()));let threads: Vec<_> = (1..=num_threads).map(|i| {let (tx, rx) = mpsc::channel::<()>();let lock = Arc::clone(&lock);let handle = std::thread::spawn(move || {let lock = lock;let mut total = 0;while let Ok(_) = rx.recv() {total += do_work(&lock, no_lock);}total});(i, tx, handle)}).collect();WebServer { threads }}pub fn send_work(&self, num_works: usize) {// --snip--}pub fn shutdown(mut self) {// --snip--}}
بیایم کد رو بازش کنیم.
تابع
do_work کار جمع کردن و لاک کردن رو برامون انجام میده.
از ورودی یک فلگ با نام
no_lock
هم داریم میگیریم که موقع اجرا در دو حالت با لاک و بدون اون رو اجرا کنیم تا ببینیم
اضافه کردن لاک چقدر توی پرفرمنس تاثیر گذاره.وب سرومون هم مولتی ترد هست
که موقع ایجاد شدن میاد به تعداد خواسته شده، ترد باز میکنه و یک لاک مشترک به همشون میده.
یک تابع با نام
send_work
داریم که کارش ارسال همزمان n درخواست با هم هست.در نهایت کار تابع
shutdown
اینه که مطمین بشه همه ترد های سرور کارشون تموم بشه و بعد سرور رو ببنده.نکته مهم: موقع اجرا کد چون ما از لاک استفادهی واقعی نمیکنیم، کامپلر راست توی پروفایلreleaseاش میاد اونو optimize میکنه. اگر میخواید کد رو اجرا کنید یا اونو تو حالتdebugاجرا کنید یا اینکه این آپشن رو به پروفایلreleaseاتون تویCargo.tomlاضافه کنید:opt-level = 2
اجرا کنیم و نتیجش رو ببینیم:
$ cargo run --releasewith lock took 20.474073198swithout lock took 3.526799261s
نتیجه ممکنه توی سیستم شما متفاوت باشه ولی چیزی که مشخص هست اینه که نسخه بدون لاک چندین برابر سریعتر هست و تاثیر زیادی
میتونه روی پرفرمنس بزاره.
برای اینکه مطمین بشیم که خود عملیات لاک کردن داره روی پرفرمنس تاثیر میزاره میتونیم با استفاده از ابزار
cargo-flamegraph
نمودار
flamegraph
اونو ایجاد کنید.
$ cargo flamegraph -c 'perf record -F 997 --call-graph dwarf -g'[ perf record: Woken up 3009 times to write data ]Warning:Processed 218901 events and lost 4 chunks!Check IO/CPU overload![ perf record: Captured and wrote 759.438 MB perf.data (92749 samples) ]writing flamegraph to "flamegraph.svg$ open flamegraph.svg
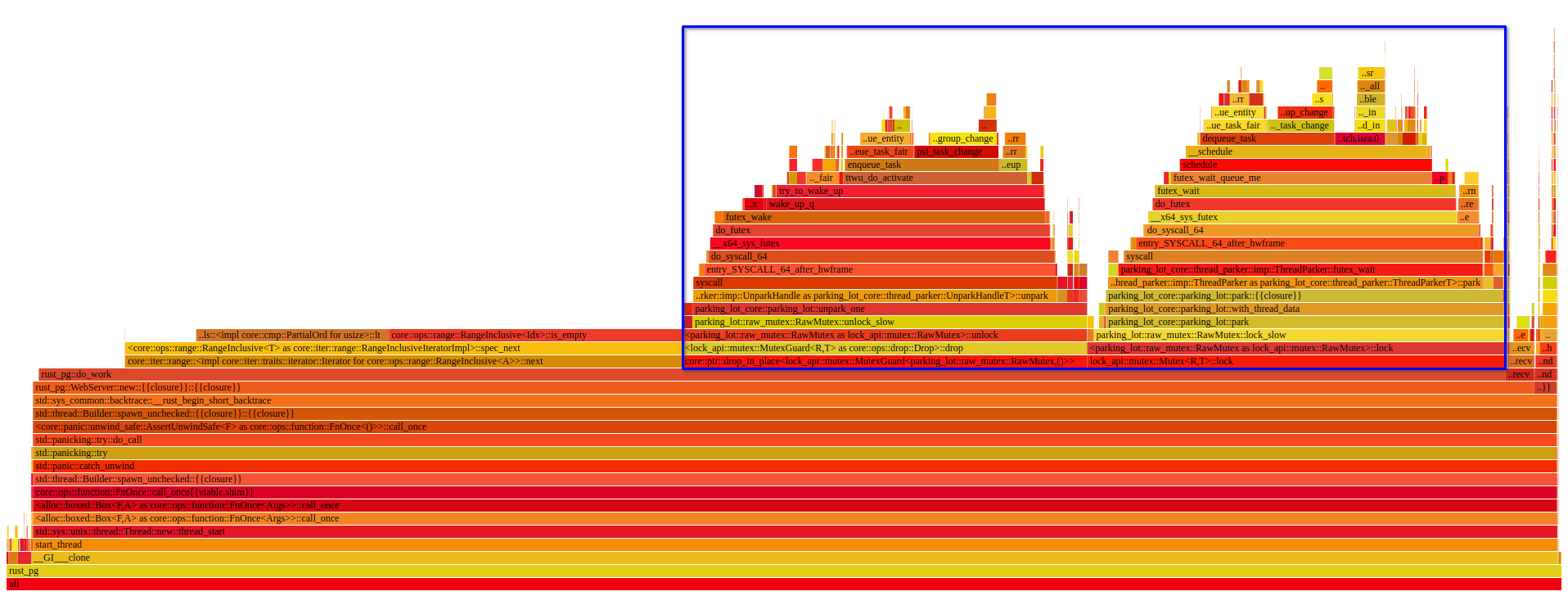
قسمت آبی، عملیات مربوط به لاک کردن مثل منتظر موندن و آنلاک شدن رو نشون میده که میبینیم حجم زیادی از زمان برنامه رو اینکار گرفته.
برای دیدن نسخه interactive و کامل نمودار بالا، اینجا را کلیک کنید.
{kind=link}
TODO: ارزششو داره بریم به راه حل های دیگه نگاه بندازیم.
- چرا وب سرور بدون همزمانی معنی نمیده. توضیح در مورد async و thread و حتی ck1000 چالش.
- مطرح کردن یک وب سرور مولتی ترد.
- اشتراک گذاری داده با استفاده mutex
- بنچمارک
- تعمیم و استفاده از futex
- بنچمارک
- استفاده از atomic بجای لاک
- معماری nginx و چالش های چند پراسسی
- توضیح دقیق در مورد اینکه دسترسی مموری توی چند پراسسی چطور هست.
- اشتراک مموری با استفاده از shared memory
- آیا استفاده از اتمیک بین پراسس ها سیف هست؟
قسمت بعدی
- روش های دیگه اشتراک مموری در چند پراسس
پانویس
منابع
[1]: