Parser چیه و توی v8 چطوری کار میکنه؟ - قسمت ۲
پارس کردن مرحلهای هست که سورس کد شما تبدیل به یک فرمت میانی قابل استفاده توسط کامپایلر میشه. چون پارس کردن در مسیر اصلی پردازش شدن یک وبسایت انجام میشه و روی لود شدن اولیه اون تاثیر مستقیم داره، خوبه که هیچ کار اضافهای انجام ندیم.
همه تابع های کد شما برای استارتاپ و اجرای اولیه سایت شما لازم نیستن.
مثلا اگه از فریمورک react استفاده میکنید، کامپوننت های شما فانکشن اند و لزوما توی یک صفحه همه کامپوننت ها دیده نمیشن
.اگه بخوایم همه کد رو همون اول پارس و کامپایل کنیم (کامپایل اینجا یعنی تبدیل AST به bytecode موتور ignition v8 هست)،
منابع سیستم رو به خوبی استفاده نکردیم.
مرورگرها برای بهتر کردن این مسئله٬ کد هارو به صورت lazy پارس میکنن و AST ای تولید نمیکنن. v8 علاوه بر این میاد کد رو pre-parse هم میکنه.
Parse کردن چی هست؟
توی مرحله قبل یعنی scanning وقتی کدو بهش میدیم یک لیست یک سطحی از توکن ها رو بهمون میده. تو مرحله parse کردن باید اونارو تبدیل به یک درخت مثل درخت زیر کنیم:
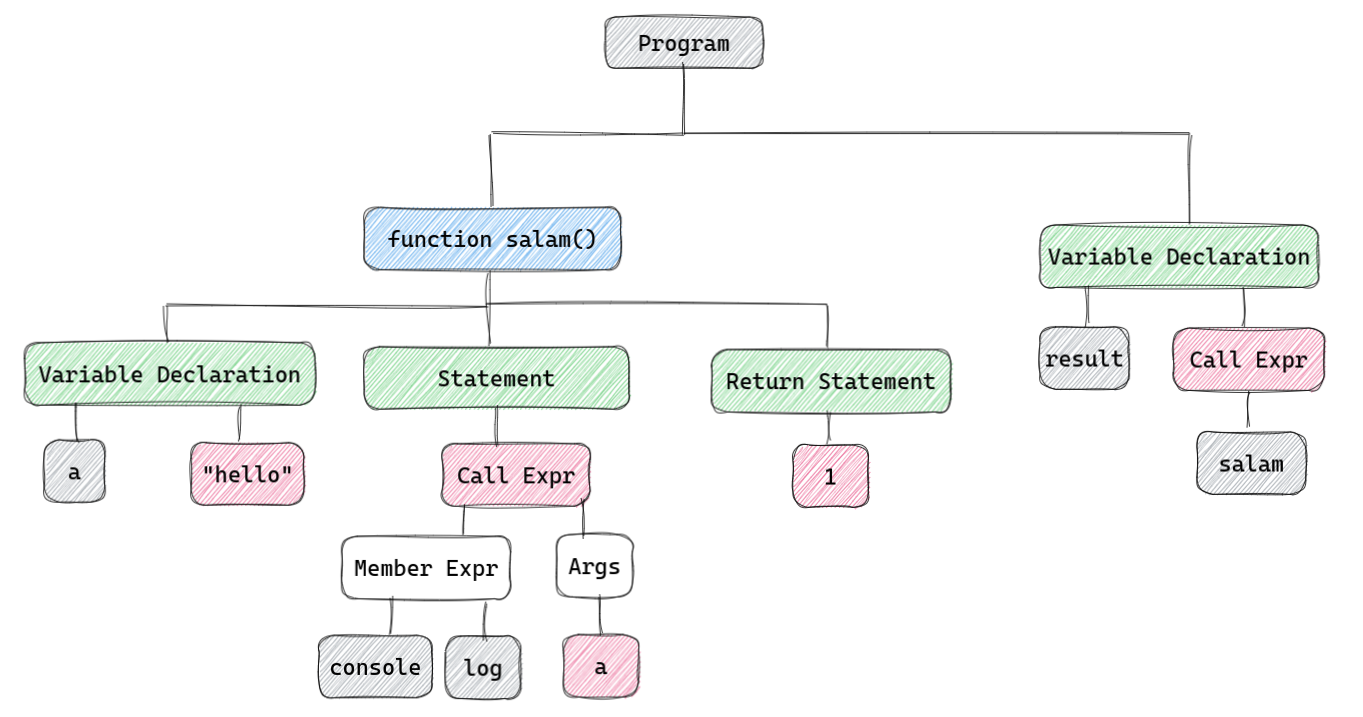
برای اینکار باید بدونیم چه توکن هایی کنار هم چه معنی ای میدن. مثلا برای یک assignment خیلی ساده حالت های زیر ممکنه:
a = 3;a.b = 3;a.c = "";a = a;
برای بهتر درک کردن این الگو ها بهتره اونارو توی فرمت یک گرامر بنویسم. مثل:
Assignment : IDENT | Member EQUAL STRING_LITERAL | NUMBER_LITERAL | IDENT | Member SEMI_COLON?Member : IDENT . IDENT Member?
بیایم گرامر بالا رو باز کنیم.
دو موجودیت اصلی اون non-terminal و terminal ها هستن.
terminal ها قوانینی هستن که نمیشه برشون داشت
و جایگزینی براشون گذاشت مثل توکن ها که توی مثال بالا terminal ها تمام حروفشون بزرگه.
non-terminal ها هم قوانینی هستن که میشه برشون داشت بجاش جایگزین گذاشت تا در نهایت به terminal برسیم.
مثل
Assignment و Member.کاراکتر
| معنی یا رو میده
و مثلا توی گرامر بالا وقتی داریم IDENT | Member معنیش این میشه که ما
میتونیم اینجا یا یک ترمینال IDENT داشته باشیم یا یک non-terminal Member. کاراکتر ? هم مشخص میکنه
که این قسمت از قانون optional هست.
همینطور قوانین میتونن به خودشون برگردن. به تعریف Member
نگاه کنید. با اینطور نوشتن قانون حالت های زیر رو میتونیم پشتیبانی کنیم:a.a , a.a.a, a.b.a.c , ...
حالا که این گرامر رو داریم نوشتن کد پارسرمون یجورایی ساده میشه. فقط کافیه همون قوانین رو مستقیم تبدیل به کدشون کنیم. به شبه کد زیر برای پارس کردن یک
Member با گرامر بالا دقت کنید:function parseMember(tokens) {if (tokens.length < 3) {return null;}const t1 = tokens[0];if (t1.type != "IDENT") {return null;}const t2 = tokens[1];if (t2.type != "DOT") {return null;}const t3 = tokens[2];if (t3.type != "IDENT") {return null;}let chain = [t1, t2];const rest = parseMember(tokens.rest());if (rest != null) {chain = [...chain, ...rest.chain];}return {type: "Member",chain,};}
مرحله pre parsing چیه؟
وقتی پارسر به یک تابع میرسه بجای اینکه بیاد کامل پارسش کنه، میاد حداقل کار رو انجام میده مثل چک کردن سینتکس و استخراج کردن متادیتا مورد نیازی که توابع بیرونی لازم دارن که صداش بزنن. مثل اسمش. وقتی این فانکشن کامل پارس و کامپایل میشه که ما اونو صداش بزنیم. این کار باعث میشه که توابع مورد نیاز برای لود اولیه یک سایت توی اولویت قرار بگیرن و استارتاپ خیلی سریعتر بشه.
اصلی ترین چالش برای pre-parser، تخصیص حافظه برای متغییر هاست. فانکشن ها توی v8 با stack صدا زده میشن تا پرفرمنس بهتری داشته باشن.
یعنی چی فانکشن ها با استفاده از stack صدا زده میشن؟
برای فهمیدن این موضوع باید بفهمیم مموری یک برنامه از چه قسمت هایی تشکیل میشه. هر برنامه ای محیط مموری مثل شکل زیر رو داره:
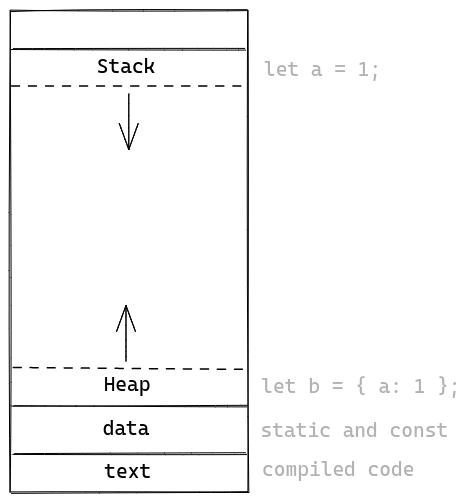
آخر این مموری یک سری داده های ثابت (با اندازه ثابت) هستند که در حالت عادی دولوپر نمی تونه اونارو تغییر بده.
این قسمت شامل کد برنامه و یک سری داده static هستند.
بعد از این داده ها یک منطقه مموری قابل گسترش قرار داره که به اون heap میگن.
Heap به سمت اول مموری گسترش پیدا میکنه.
سمت آخر و اول یعنی اگر مثلا یک معماری داشته باشیم که اشارهگرش نهایتن بتونه به آدرس x اشاره کنه و اولین آدرس،
آدرس ۰ باشه، Heap از
x - sizeof(static data) شروع میشه.
اگر یک داده با اندازه ۸ بیت داشته باشیم بخوایم اونو بریزیم توی Heap
باید ابتدا ۱ بایت حافظه براش بگیریم (allocate) کنیم.
اگر این تخصیص رو انجام بدیم شروع این رنج حافظه heap_start - 1 و آخر اون
heap_start میشه. اگه داده بعدیمون ۱۶ بیت باشه شروعش heap_start - 3 و
پایانش اول داده اولمون هست که میشه heap_start - 1 و تا آخر…قسمت دیگه قابل تغییر این مموری استک هست که باید فاصلهای
از شروع مموری برنامه شروع میشه و به سمت آخر رشد میکنه.
فرق این دوتا مموری اینه که توی استک فقط میتونیم
به آخر استک چیزی اضافه کنیم و اگه بخوایم
یک مقدار رو پاک کنیم، باید تمام مقدار هایی
که قبلش اضافه کردیم هم پاک کنیم.(همون ساختار داده stack) مثل چنتا ماشین توی یک کوچه تنگ که اگه ماشین آخری بخواد
بیاد بیرون باید اول همه
ماشین های جلوش بیان بیرون.جدا از اون همه داده
ها باید موقع کامپایل سایز مشخصی داشته باشن.
اما Heap این محدودیت رو نداره و می تونیم با هرالگویی و سایزی دیتا اضافه کنیم یا کم کنیم یا جابجا کنیم.
(قطعا تا جایی که مموری کافی داشته باشیم) حالا چرا stack از heap سریعتر هست؟
در اصل همین
محدودیت توی نحوه دسترسی به داده (Access pattern) که داخل stack هست باعث میشه که الگوی دسترسی قابل پیشبینی داشته باشه (که این الگو خطی هست)
و این در نهایت باعث میشه که بتونیم از CPU Cache استفاده زیادی ببریم و همینطور CPU (و کامپایلرها)
میتونن با پیشبینی های خودشون از برنامه نسبت به فرض الگوی دسترسی که داریم، برنامه مارو بهینهتر اجرا کنند.
اما چون Heap الگوی مشخصای برای دسترسیش مشخص نیست، این بهینه سازی ها خیلی سختتر انجام میشن.
در اصل اگر برنامهها بخوان بصورت پویا به یک دادهای داخل Heap دسترسی داشته باشن باید حتما از
stack استفاده کنن. معمولا یک ساختار داده هایی هستن که بهشون Proxy میگن. مثلا یک چیزی مثل استرینگ که
سایز مشخصی نداره ساختار دادهای
مثل شکل زیر داره:
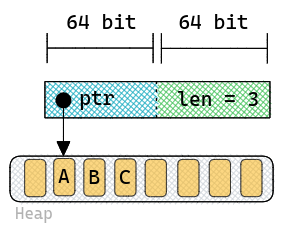
یک struct با اندازه ثابت داره که داخلش
یک پوینتر و یک اندازه قرار داره. این پوینتر به یک قسمتی از heap اشاره میکنه (کاراکتر اول) و میتونیم با اضافه کردن اندازه به این
پوینتر مشخص کنیم
پایان این رشته توی Heap کجاست. این struct داخل
استک قرار میگیره که یک Proxy struct هست و با استفاده از اطلاعات این پراکسی میتونیم خود رشته رو از Heap بخونیم.
حالا برگردیم به صدا زدن فانکشن ها با استفاده از stack. توابع با قرارداد های مختلفی صدا زده میشن که زیاد نمیخوام
بهشون بپردازم ولی خیلی کلی وقتی ما یک تابع رو
صدا میزنیم باید به یک طریقی پارامتر هارو برای اون تابع
بفرستیم تا اون بتونه ازشون استفاده کنه. فرض کنیم یک
تابع داریم که دوتا ورودی عدد میگیره.
برای صدا زدن این تابع اول میایم دوتا پارامتر رو به stack اضافه میکنیم و وارد تابع میشیم. تابع میدونه که دوتا ورودی داره و موقع شروع اجراش
میدونه از کجا شروع شده پس میتونه با خوندن
دوتا المان آخری stack پارامتر هارو بخونه.
حالا کار تابع تموم شده میخواد برگرده.
کافیه دو المان آخر
(و همه دیتا های لوکالی که داخل خودش درست کرده) رو pop کنه مقدار return
رو توی استک پوش کنه و برگرده به تابع قبلی. اینطوری تابع قبلی فقط یک
داده اضافه داره و
اون همون مقدار return value تابعی ای هست که داخلش صدا شده.
حالا توی جاوااسکریپت
اگه ساختار دادهای نداشته باشیم که نیاز به Heap و proxy struct داشته باشه کافیه فقط با همین استک به فانکشن های مختلف پاسشون بدیم.
مثلا یک عدد رو میتونیم پوش کنیم توی استک.
بعضی وقتا هم نمیتونیم اینکارو کنیم مثلا اگه بخوایم یک استرینگ پاس بدیم به یک تابع باید اول توی Heap
اونو ذخیره کنیم
و یک proxy struct یا پوینتر تنها داشته باشیم که
(سایز ثابتی داره) و اون پراکسی
رو به استک پوش کنیم. توی این حالت از Heap برای پاس دادن داده استفاده کردیم که همینطور که گفتیم پرفرمنس بدتری نسبت به استفاده مستقیم از استک داره.
برای فهم بهتر به مثال زیر نگاه کنیم:
function f(a, b) {const c = a + b;return c;}function g() {return f(1, 2);}
وقتی توی تابع
g() میخوایم تابع f() رو صدا بزنیم٬ اول میایم توی استک this که اینجا globalThis
هست رو پوش میکنیم. سپس آرگومان های داده شده که اینجا 1 و 2 هستن، در نهایت هم توی یک پوینتر مخصوص به نام rip باید آدرس جایی که باید بهش برگردیم رو بریزیم.
حالا میتونیم بریم داخل تابع f(). وقتی توی تابع به یک return رسیدیم کافیه که استک رو تا اولین مقداری که پوش کردیم، پاپ کنیم، نتیجه تابع رو توی استک پوش کنیم و درنهایت با استفاده از rip به تابع قبلیمون یا همون g() برگردیم.
حالا برگردیم به مشکل قبلی، چرا این برای pre-parser مشکل سازه؟ به کد زیر دقت کنید:
function make_f(d) {// ← declaration of `d`return function inner(a, b) {const c = a + b + d; // ← reference to `d`return c;};}const f = make_f(10);function g() {return f(1, 2);}
تفاوت این کد با کد قبلی استفاده از
closure هست. توابعی که یکسری رفرنس به مقادیری دارن که از ورودی بهشون داده نشده.
این مقادیر توی v8 توی یک چیزی به نام context به توابع موقع صدا زدن پاس داده میشه.
توی این مثال وقتی make_f رو صدا میزنیم یک تابع میسازیم که به ورودی که اول بهش دادیم (۱۰) نیاز داره.
این تابع معلوم نیست کی قراره صدا زده بشه پس
نمیتونیم توی استک نگهش داریم. پس مجبوریم ببریمش روی هیپ.
توی این حالت هایی که یک تابع یک تابع دیگهای رو تولید میکنه
که تابع داخلی به یک سری چیز از بیرون رفرنس داره بهش میگن closure و context یک proxy structure
ای هست که این رفرنس هارو نگه میداره و
کنار این closure نگهداری میشه تا هر وقت خواستیم این تابع رو صدا بزنیم، این context رو هم بهش بدیم:
چون داریم pre-parse میکنیم میخوایم خیلی سریع از body تابع بگذریم و همینجا که نمیدونیم باید موقع صدا زدن چه آرگومان هایی رو ببریم روی Heap چالش درست میکنه. اگه بخوایم همه ورودی های یک تابع رو ببریم روی Heap که خیلی رو پرفرمنس توابعی تاثیر میزاره که ورودی های سادهای مثل عدد میگیرن. اینجا توی v8 باید یکم از سرعتی که pre-parser داره بزنیم و حداقل variable هارو track کنیم. چطور اینکارو بهینه انجام میده؟ یک پست جدای خودش رو لازم داره و بیشتر رفتن تو detail این قسمت ممکنه خسته کننده بشه. احتمالا یک پست جدا باز این سری براش درست کنم و قسمت بعدی بریم وارد قسمت های جذابتر v8 بشیم.
مثل کامپایلر اون. توی قسمت بعدی نگاه میکنیم به interpreter ignition که داخل v8 وجود داره. اولین قسمتی که کد مارو واقعا اجرا میکنه.